How to protect your website that is on Cloudflare ?
(Last update May. 6. 2024.)
Don’t expect that if you just set up the CF nameservers everything will be well.
Cloudflare is a tool, that you need to understand, learn and put to work for you after proper configuration.
We often have the opportunity here on the forum to see that some websites have been suspended for exceeding the limit and mostly this is caused by a bunch of bots doing a vulnerability scan and searching sensitive directories and files on your site.
Some of these bots are very reckless and do over 30 requests in one sec!
An example of what it looked like on my website:
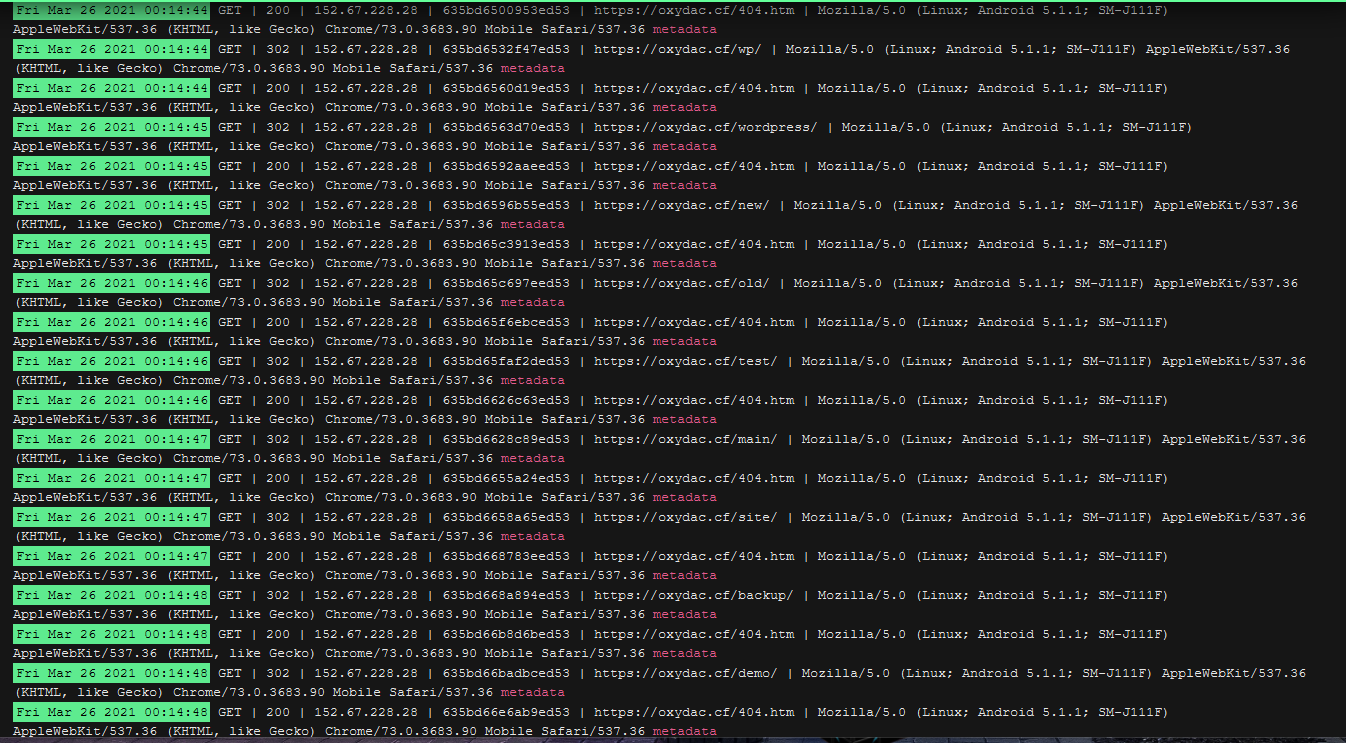
Analytics from CF (nearly a million requests and generated 20GB of traffic)




Fortunately, a large part of my website is static content, so everything was served by CF (20GB).
Imagine what it’s like for someone who has WordPress and every time the server has to generate the pages that BOT requests.
This kind of behavior drains system resources, hogs bandwidth, and prevents your site from operating at maximum capacity.
After my reaction, the situation is like this

To protect yourself
You first need to see the logs which are not possible *1 if you use the free plan on Cloudflare
Currently, to install Logflare on Cloudflare, use these instructions
and ignore the others = How to do logging in Logflare and its installation on Cloudflare
(So it is good to install this application on Cloudflare https://www.cloudflare.com/apps/logflare
Official site and help https://logflare.app/
You can find more information about it here Logflare CloudFlare App - Review | Nick Samuel)
*1 Thanks to @anon56079534 we also have an alternative to Logflare directly on CF - look here
Once you set up the app
You can access the logs on their website or like me generate a public link which you can then put in bookmarks, so you don’t have to log into their system…
Instead of that - you just watch logs directly in real time.

Scroll until you see this section (and generate a URL)

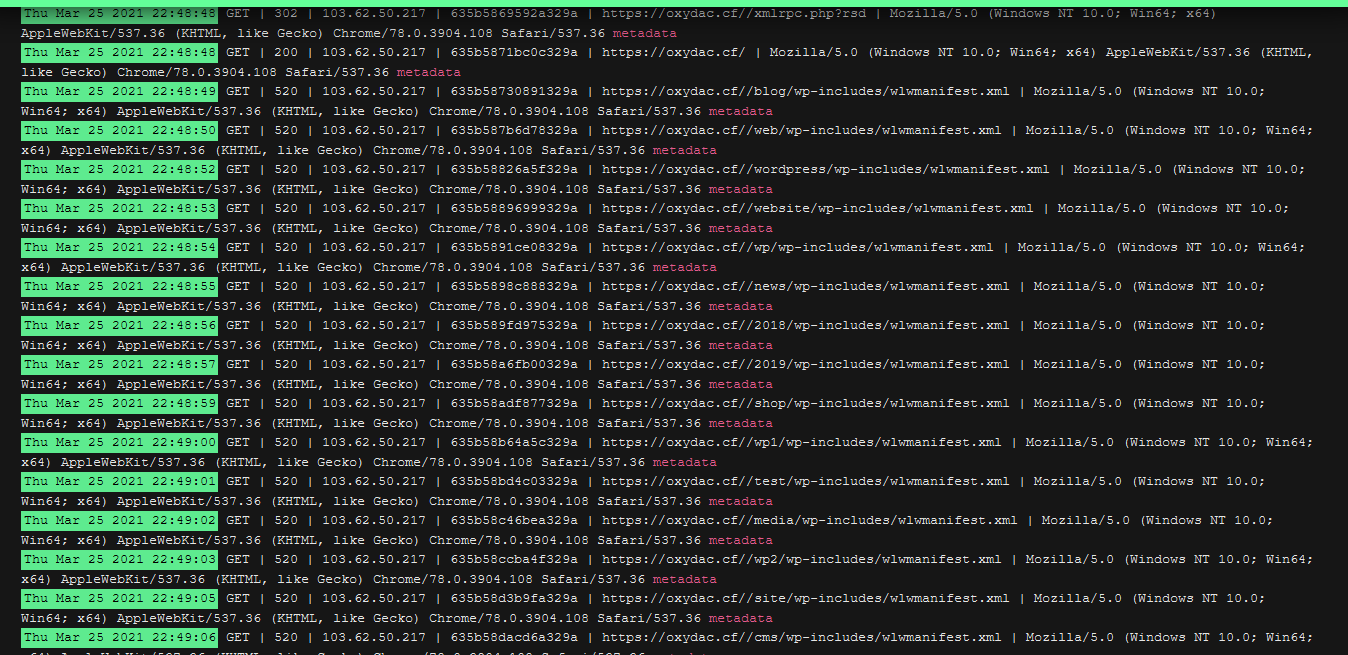
Then look in logs for unwanted guests
and by what these bots do on your site (request) you generate firewall rules on your CF
In this example, you see that the bot searches the file wlwmanifest.xml non-stop in different locations.
and bots can often try over 500 locations in a matter of seconds which of course burdens your origin

So instead of dealing with IP blocking nonstop
(this doesn’t mean you shouldn’t do it)
you can shorten the job by generating FW rules
Hint: use OR in FW rules so you save a number of free rules
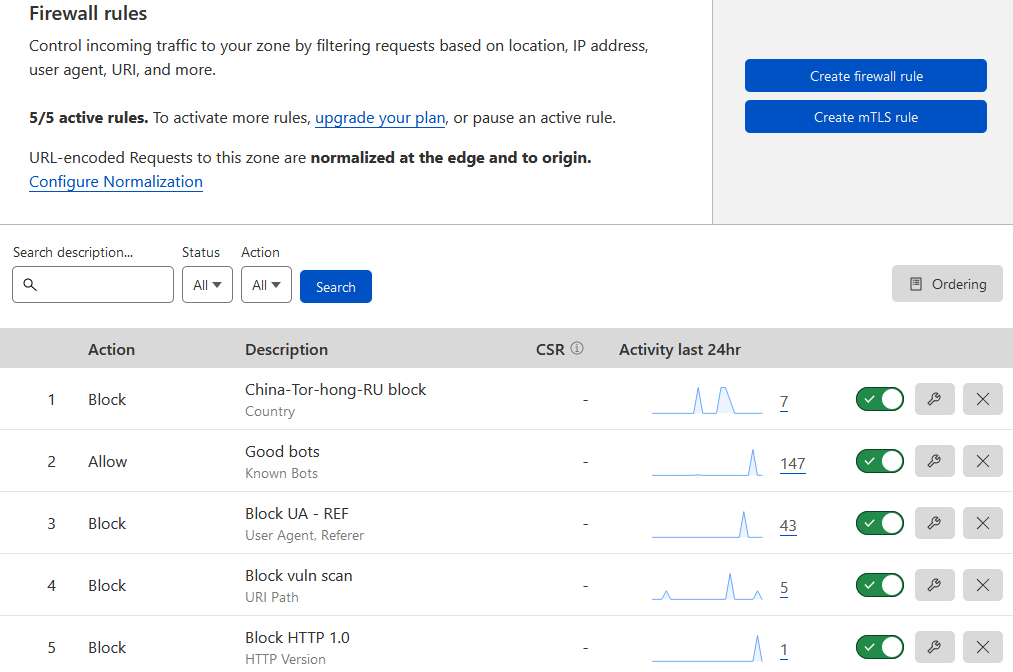
The example I use is just for my website !!!
because I don’t have WordPress and I can then “easily” decline some requests


If anyone wants these rules (note I don’t use WP)
you can click on CF FW rules edit expression
and paste my code inside

Rule 1 (user agents) bad bots engines
(http.user_agent contains "python-requests") or (http.user_agent contains "Python-urllib") or (http.user_agent contains "Apache-HttpClient") or (http.user_agent contains "Nuclei") or (http.user_agent contains "MJ12bot") or (http.user_agent contains "httpx") or (http.user_agent contains "MauiBot")
Rule 2 (files and paths) vuln. scan
(http.request.uri.path contains "wlwmanifest.xml") or (http.request.uri.path contains "wp-includes") or (http.request.uri.path contains "xmlrpc.php") or (http.request.uri.path contains ".env") or (http.request.uri.path contains "wp-content") or (http.request.uri.path contains "eval-stdin.php") or (http.request.uri.path contains "wp-login") or (http.request.uri.path contains "wp-admin")
The code above (about WordPress dirs) can also be shortened quite a bit by using this
(http.request.uri.path contains "/wp-")
but I intentionally did not use it because maybe someone has such a beginning of the name for file or dir
so it would be problematic.
It is advisable to do this also - so that no one circumvents the FW rules
URL normalization modifies separators, encoded elements, and literal bytes in incoming URLs
so that they conform to a consistent formatting standard.
For example, consider a firewall rule that blocks requests whose URLs match example.org/hello.
The rule would not block a request containing an encoded element — example.org/%68ello.
Normalizing incoming URLs at the edge helps simplify Cloudflare firewall rules expressions that use URLs.
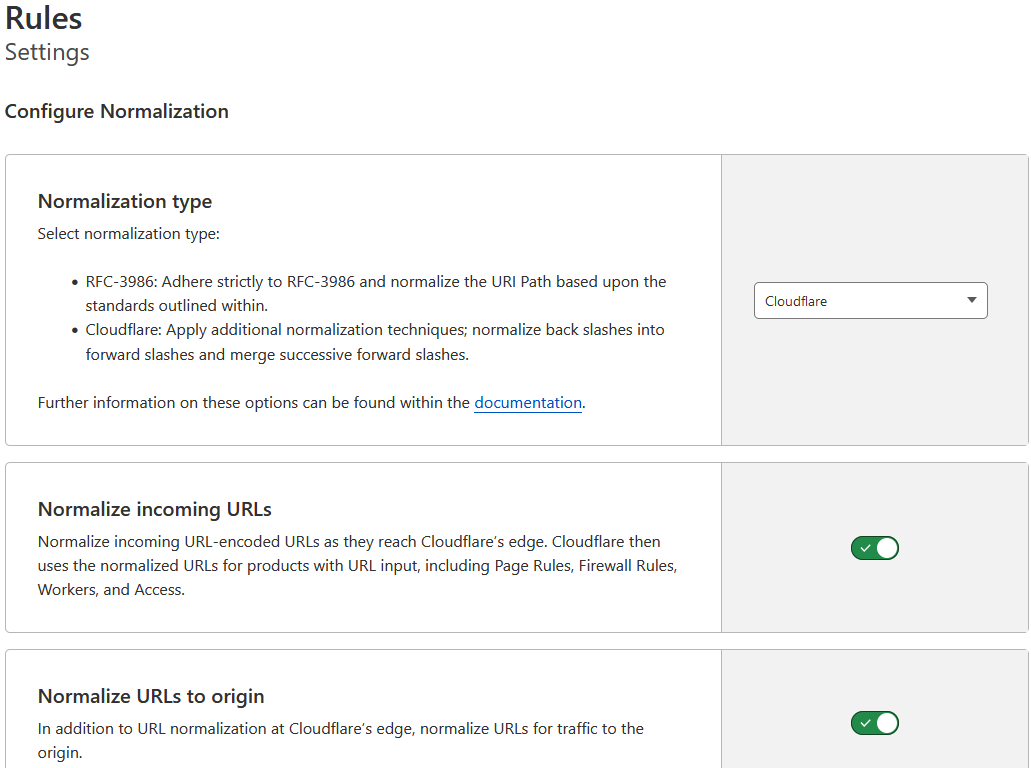
For more information about chars and more see here.
Besides, new users on CF have this ON by default, but for older users - turn it on
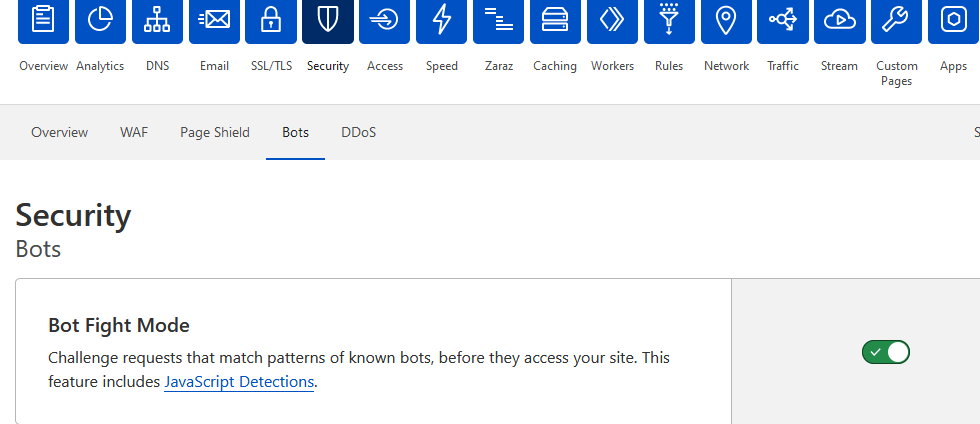
If the bots pass the JS challenge you can further reduce their expiration time here

block IP here
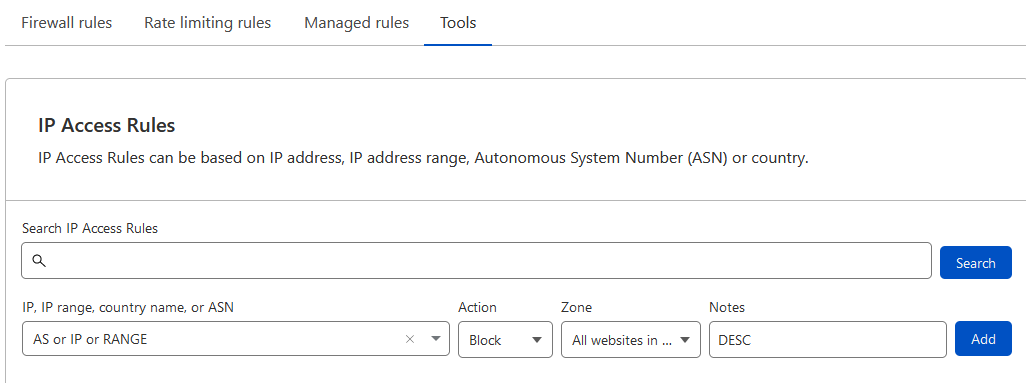
If you are not sure about an IP (or ASN - AS ) before the block be sure to look at whois/IPinfo
and some of the sites like (enter the IP in the search field )
And/or click on the metadata in the log (Logflare)

Monitor the situation here

And then you spend approx 10 days watching the logs every day and checking analytics,
and after that, you have created enough FW rules to repel most malicious bots.
Periodically do some necessary updates to existing Firewall and IP rules.
You can add to your firewall rule an exclusion to the “Known Bots” operator
so those legit crawlers such as Googlebot aren’t blocked if they touch a URL that is blocked (trigger) by some other FW rules.

The list of bots is maintained by the CF and checked by IP and other validation methods,
so you have nothing extra to do other than turn it ON and allow it.
Cloudflare verified Bots list
Just in case, move the rule to the first position (grab and move)
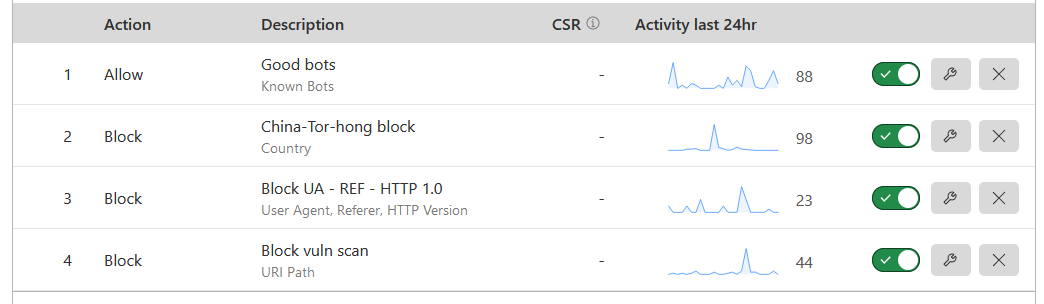
All this above is the starting point
I intentionally did not share my complete configuration
because I don’t want to jeopardize my site by publicly showing someone how to circumvent all my rules
But one of the more important activities is to block hosting (WAF/tools)
most attacks/scans will come from there
Digitalocean = AS14061
Amazon = AS14618 , AS16509
Microsoft = AS8075
OVH = AS16276
(and hundreds more on the list)
Of course, some online sites (tools) that are on those servers will no longer work because your site will deny them access
so if necessary, you can temporarily turn off a block and when you finish with the desired “test” (online) re-enable the block.
Useful - to understand the order
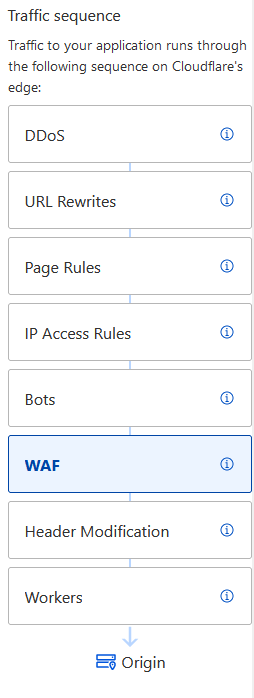
Useful links for better understanding
In addition to everything mentioned at the beginning of the topic
it is preferable to allow only Cloudflare servers to access the origin
note: it is recommended to put that part of the code on top of the .htaccess code
CF side:


At some point, if attacks go beyond normal complexity,
you need to add a rate limit, session inspection, and fingerprinting. Going beyond that is most of the time absurd.
Relying on CAPTCHA or JS Challenges for complex attacks is foolish, it’s always been like that.
Everybody knows that attacks can solve those two challenges, these layers are made to add costs and complexity to attacks.
When bot operators realize that their bots are being blocked, many will simply stop trying and look for another victim instead (hopefully not you).
Good luck and thank you for your time ![]()






